【AWS】EC2のGPUインスタンスについて解説します。
話題のディープラーニングの学習には、高性能なGPUが欠かせません。ところが、ディープラーニングに適した高性能GPUを搭載しているサーバーは非常に高価で、気軽に導入できるものではありません。しかし、AWSのようなクラウドコンピューティング環境を用いることで、初期投資なしでGPUを使ったディープラーニングを始めることができます。
GPUを搭載したAWSのEC2インスタンスには、PインスタンスファミリーとGインスタンスファミリーが存在します。ここでは、それぞれの特徴や仕様について解説します。
■AWSのGPUインスタンス
AWSのEC2では、GPU(高速コンピューティング)インスタンスとして主にPインスタンスとGインスタンスが用意されており、ハードウエアアクセラレーター(コプロセッサ)を使用して、浮動小数点計算、グラフィックス処理、データパターン照合などの機能を、CPUで実行中のソフトウェアよりも効率的に実行します。
【Gインスタンスファミリー(G4、G3)】
Graphic用途のNVIDIAの最新アーキテクチャであるTuringを採用したGPUを搭載しています。G4インスタンスについては2019年9月より利用が可能になった新しいインスタンスです。最新アーキテクチャにも関わらず、G4インスタンスはコストの安さが際立っています。
【Pインスタンスファミリー(P3、P2)】
NVIDIA K80 GPU(P2) / NVIDIA Tesla V100 GPU(P3)を搭載しています。本来グラフィック計算用途として使用されていましたが、数値計算に強いという性質からビットコインの採掘(マイニング)などの単純計算を高速に行うことに長けており、グラフィック以外の目的で利用され始めています。
■G4
最新のGPU対応インスタンスです。G4インスタンスは、機械学習推論やグラフィックを大量に使用するワークロードを迅速化するために設計されています。
- 特徴
- ・AWSカスタムIntel CPU(4~96個のvCPU)
- ・1~8個のNVIDIA T4 Tensor Core GPU
- ・最大384GiBのメモリ
- ・最大1.8TBの高速でローカルなNVMeストレージ
- ・最大100Gbpsのネットワーク
用途例:画像へのメタデータ追加、オブジェクト検出、レコメンドシステム、自動音声認識、言語翻訳といったアプリケーションの機械学習推論などに向いています。また、G4インスタンスを使用すると、リモートグラフィックワークステーション、動画トランスコーディング、フォトリアリスティックの作成、クラウド上のゲームストリーミングなど、グラフィックを大量に使用するアプリケーションの構築および運用を行うための非常にコスト効率が良いプラットフォームを実現できます。
■G3
G3インスタンスは、グラフィック集約型アプリケーション用に最適化されています。Citrix XenApp EssentialsおよびVMWare Horizonなどのアプリケーション仮想化ソフトウェアのために、NVIDIA Virtual Application機能を有効化し、GPUごとに最大25人の同時ユーザーをサポートできます。
- 特徴
- ・AWSカスタムIntel CPU(4~64個のvCPU)
- ・それぞれに2048個の並列処理コアと、8GiBのビデオメモリが搭載されたNVIDIA Tesla M60 GPU
- ・最大解像度4096×2160のモニター4台のサポートを含む、NVIDIA GRID Virtual Workstation機能を有効化
- ・プレイスメントグループ内における、25Gbpsの集約ネットワーク帯域幅(Elastic Network Adapter・ENA)を使用した拡張ネットワーク
用途例:3Dビジュアライゼーション、グラフィック負荷の高いリモートワークステーション、3Dレンダリング、アプリケーションストリーミング、動画エンコーディングおよびその他のサーバー側グラフィックワークロードに向いています。
■P3
P3インスタンスは、汎用GPUインスタンスの最新世代です。中でも、p3dn.24xlargeインスタンスにおいては、ハイパフォーマンスコンピューティング(HPC)アプリケーションが多数のGPUに対応できる仕様になっています。
- 特徴
- ・高クロックのIntel Xeon E5-2686 v4(Broadwell)プロセッサ※p3.2xlarge、p3.8xlarge、p3.16xlarge向け
- ・高クロックの2.5GHz(ベース)Intel Xeon P-8175Mプロセッサ※p3dn.24xlarge向け
- ・5120のCUDAコアと640のTensorコアがペアとなったNVIDIA Tesla V100 GPUを最大8つ提供
- ・ピアツーピアのGPUに通信を行うNVLinkをサポート
- ・最大100Gbpsの集約ネットワーク帯域幅を提供
- ・p3dn.24xlargeインスタンスでのEFAサポート
用途例:機械学習や深層学習、ハイパフォーマンスコンピューティング(HPC)、計算流体力学、金融工学、耐震解析、音声認識、自律走行車、創薬など幅広く対応できます。
■P2
P2インスタンスは、汎用GPUコンピューティングアプリケーション用に設計されています。
- 特徴
- ・高クロックのIntel Xeon E5-2686 v4(Broadwell)プロセッサ
- ・それぞれに2496個の並列処理コアと12GiBのGPUメモリが搭載された、高性能のNVIDIA K80 GPU
- ・ピアツーピアのGPU通信のためのGPUDirect™をサポート
- ・プレイスメントグループ内において、最大25Gbpsの集約ネットワーク帯域幅(Elastic Network Adapter・ENA)を使用する拡張ネットワーキングを提供
- ・デフォルトでEBS最適化、追加料金なし
用途例:機械学習、ハイパフォーマンスデータベース、計算流体力学、金融工学、耐震解析、分子モデリング、ゲノミクス、レンダリング、サーバー側のその他のGPUコンピューティングワークロードに向いています。
~参考~
- ※NVIDIA T4 GPU
- 真新しいNVIDIA T4 GPUは、320個のTuring Tensor Core、2560個のCUDA Coreと16GBのメモリを搭載しています。Machine Learning推論およびビデオ処理のサポートに加えて、T4はリアルタイムストレーシング用のRT Coreを含み、NVIDIA M60の最大2倍のグラフィックス性能を提供できます。
- ※EFA(Elastic Fabric Adapter)サポート
- ハイパフォーマンスコンピューティング(HPC)と機械学習アプリケーションを高速化するために、Amazon EC2インスタンスにアタッチできるネットワークデバイスです。EFAでは、AWSクラウドが提供するスケーラビリティ、柔軟性、伸縮性により、オンプレミスのHPCクラスターのアプリケーションパフォーマンスを実現できます。
- ※ENA(Elastic Network Adapter)
- EC2インスタンスで高スループット、高いパケット毎秒(PPS)、安定した低レイテンシーを実現できるよう最適化されたカスタムネットワークインターフェースです。ENAを使用すると、特定のEC2インスタンスタイプで最大20Gbpsのネットワーク帯域幅を利用できます。
■料金
それぞれの料金体系は以下のようになっています。
・G4
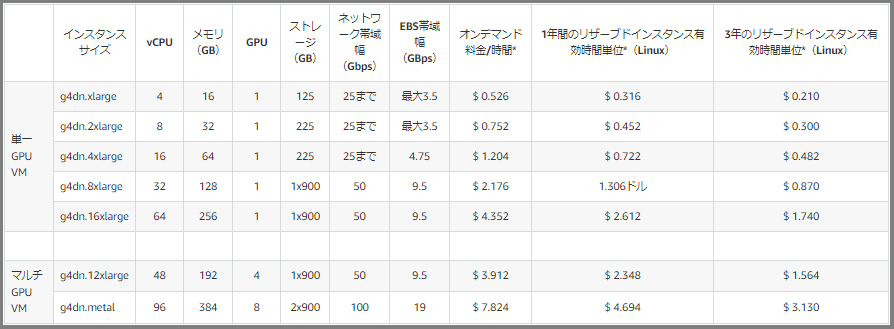
・G3

・P3
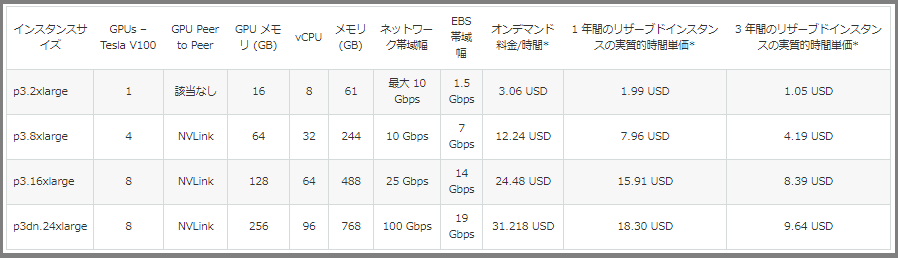
・P2
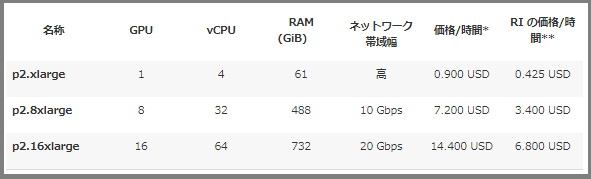
■あとがき
自身でGPU環境を構築し利用しようとすると、学習を始めるまでに必要な環境構築があまりにも大変だったり、手順が多いなどでうんざりしてしまうことが多いと思います。しかし、ディープラーニングなどに必要な環境がプリインストールされたAWSのマシンイメージを利用することにより、簡単にGPUを使った学習を行うことができます。クラウドで手軽にテストしてみたい場合などは、簡単に環境を用意することができるため、この機会にGPUの環境を利用してみるのはいかかでしょうか。
参考文献:
https://qiita.com/fjisdahgaiuerua/items/893a1e498b5938216436
https://stra.co.jp/aws/2020/04/30/185/
https://www.blog.v41.me/posts/ba137bd3-13cc-4b25-9f04-11f7b474a84e

